


Recuperar tablas huérfanas .ibd para almacenamiento transaccional innodb
5 de enero de 2024
Gestión de almacenes de certificados keystore Java, comandos mas habituales.
13 de febrero de 2024Procedimiento para habilitar el registro de estadísticas en nuestras bases de datos Postgresql a través de la libreria pg_stat_statements, una de las extensiones mas potentes, utiles e imprescindibles de Postgresql. Realizaremos también una pequeña optimización de parámetros al final del artículo.
1.- Instalamos el paquete postgresql-contrib en caso de no tenerlo instalado.
2.- Modificamos el archivo postgresql.conf y habilitamos:
shared_preload_libraries = 'pg_stat_statements'
compute_query_id = on
pg_stat_statements.max = 10000
pg_stat_statements.track = all
3.- Comprobamos que está creada la tabla con sus columnas.
\d pg_stat_statements;
4.- Conectaremos con la base de datos que queramos recolectar estadísticas y crearemos la extensión puesto que hay activarlo por cada base de datos a monitorizar.
\c my_database
CREATE EXTENSION IF NOT EXISTS pg_stat_statements;
5.- A partir de aquí ya podemos hacer debug de nuestras queries y determinar cuales de ellas son las que están provocando un alto consumo de recursos (memoria/CPU) en nuestro servidor.
Consultas SQL ordenadas por uso de CPU
SELECT
pss.userid,
pss.dbid,
pd.datname as db_name,
round((pss.total_exec_time + pss.total_plan_time)::numeric, 2) as total_time,
pss.calls,
round((pss.mean_exec_time+pss.mean_plan_time)::numeric, 2) as mean,
round((100 * (pss.total_exec_time + pss.total_plan_time) / sum((pss.total_exec_time + pss.total_plan_time)::numeric) OVER ())::numeric, 2) as cpu_portion_pctg,
substr(pss.query, 1, 200) short_query
FROM pg_stat_statements pss, pg_database pd
WHERE pd.oid=pss.dbid
ORDER BY (pss.total_exec_time + pss.total_plan_time)
DESC LIMIT 30;
TOP 10 most Total_Exec_time intensive queries
select userid::regrole, dbid, query
from pg_stat_statements
order by total_exec_time desc
limit 10;
TOP 10 most I/O intensive queries
select userid::regrole, dbid, query
from pg_stat_statements
order by (blk_read_time+blk_write_time)/calls desc
limit 10;
TOP 10 memory usage queries
select userid::regrole, dbid, query
from pg_stat_statements
order by (shared_blks_hit+shared_blks_dirtied) desc
limit 10;
Ahora podemos depurar nuestras consultas SQL con un buen criterio y optimizar aquellas que consumen más recursos en el servidor.
Documentación oficial del módulo de estadísticas:
https://www.postgresql.org/docs/current/pgstatstatements.html
Otra opción debería ser hacer un SELECT con los prefijos EXPLAIN ANALYZE para evaluar las consultas más lentas obtenidas en pg_stat_statements para evaluar la mejor estrategia y optimización de consultas:
https://thoughtbot.com/blog/reading-an-explain-analyze-query-plan
Más consultas que muestran actividad:
Finalmente observamos el uso de trabajadores paralelos en el archivo stat_activity, se debe revisar la configuración de este parámetro ya que también se puede personalizar. Más información aquí:
https://www.pgmustard.com/blog/max-parallel-workers-per-gather
Acerca del uso elevado de CPU, de hecho, se recomienda encarecidamente pg_stat_statements para obtener información adicional:
https://www.cockroachlabs.com/blog/high-cpu-usage-postgres
Optimizacion adicional desactivada por defecto en Postgresql (valor por defecto vacuum 20%)
# DB Version: 15
# OS Type: linux
# DB Type: mixed
# Total Memory (RAM): 16 GB
# CPUs num: 16
# Connections num: 100
# Data Storage: ssd
max_connections = 100
shared_buffers = 4GB (25% Ram capacity aprox.)
effective_cache_size = 12GB
maintenance_work_mem = 1GB
checkpoint_completion_target = 0.9
wal_buffers = 16MB
default_statistics_target = 100
random_page_cost = 1.1
effective_io_concurrency = 200 (200 for SSD, 300 for SAN)
work_mem = 5242kB
huge_pages = on
min_wal_size = 1GB
max_wal_size = 4GB
max_worker_processes = 16
max_parallel_workers_per_gather = 4
max_parallel_workers = 16
max_parallel_maintenance_workers = 4
track_counts = on
autovacuum = on
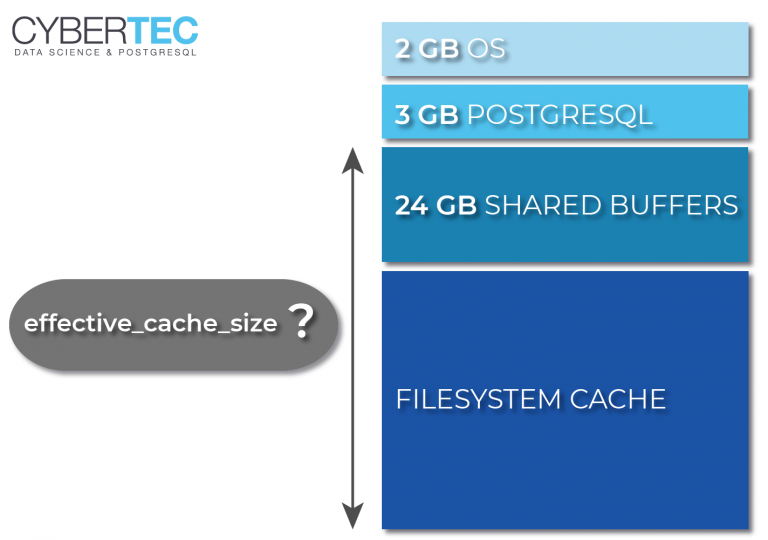
Explicación genérica de parámetros de optimización:
https://www.metisdata.io/blog/postgresql-on-steroids-how-to-ace-your-database-configuration
Y con estos pequeños ajustes y modificaciones ahora tenemos nuestra base de datos en unas condiciones óptimas para mejorar su rendimiento sustancialmente.
